
Hi Guy’s Welcome to Proto Coders Point, In this Tutorials we will learn about the Microsoft Azure Database and How to import data from csv file to sql database
Requirements: –
- IDE or Notebook
- Database Credential
- JDBC Connection
1) IDE or Notebook
It is web interface that contain runnable commands, visualizations, We create notebook using some default languages i.e. Python, SQL, Scala, R, Pyspark.
2) Database Credentials: –
We need to make sure that all Database Credentials are required to connect with the Database i.e. Server Name, Database Name, ID, Password.
3) JDBC Connection: –
Connection is used to load the driver and help to establish connect with the Data Source.
4) CSV FILE:-
Comma-Separated Value is a text file which data is available in spreadsheet format.
Creating SQL Database on Azure Cloud
First of all, We Need to Create a SQL Database on Azure. We have shared some step that help you to create SQL Database.
- Go to Search Tab in Azure.
- Search for ‘SQL Database’ & click on It.
- Click on ‘Create’.
- Add project Details
- Subscription
- Resource Group
- Database Details
- Database Name (Add Database Name)
- Server Name (Choose Same Region that are already defined in SQL Server)
- Workload Environment – Choose development OR Production Environment
- Compute + Storage –
- Add project Details

- Backup Storage Redundancy
- Choose Locally OR Geo Storage Redundancy
Connect databricks to sql server using python code
After creating a Database in Azure we will try to connect to Database Using Data bricks: –
While accessing a Database azure we have certain ways to connect like CLI, Programming, SQL Server Management Studio.
We are going to use Python Programming for accessing Database with JDBC Connection (databricks connect to sql server python).
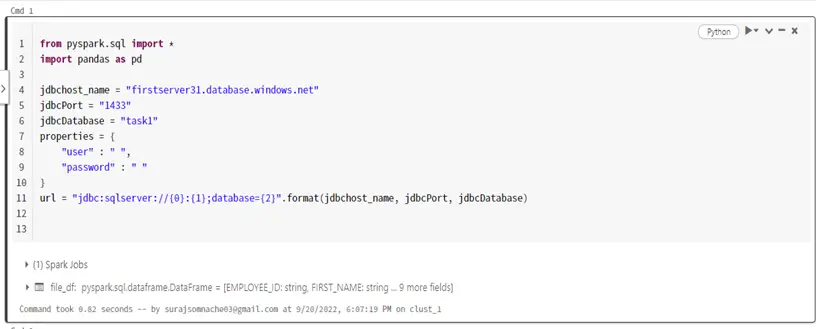
Step 1:- First will connect with the SQL Database by using JDBC Port:
from pyspark.sql import *
import pandas as pd
jdbchost_name = "firstserver31.database.windows.net" //Server Name
jdbcPort = "1433"
jdbcDatabase = "task1" //Database Name
properties = {
"user" : " ",
"password" : " "
}
url = "jdbc:sqlserver://{0}:{1};database={2}".format(jdbchost_name, jdbcPort, jdbcDatabase)
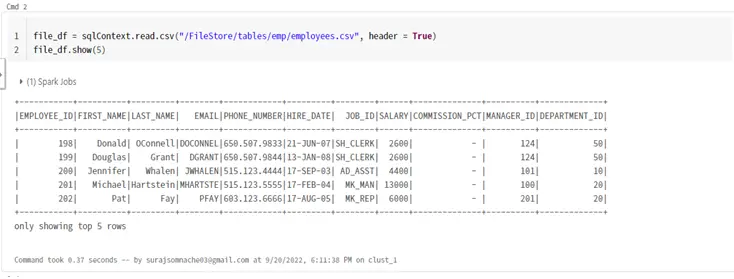
Step 2:- After connecting with the Database we will read a CSV file
file_df = sqlContext.read.csv("/FileStore/tables/emp/employees.csv", header = True)
file_df.show(5)
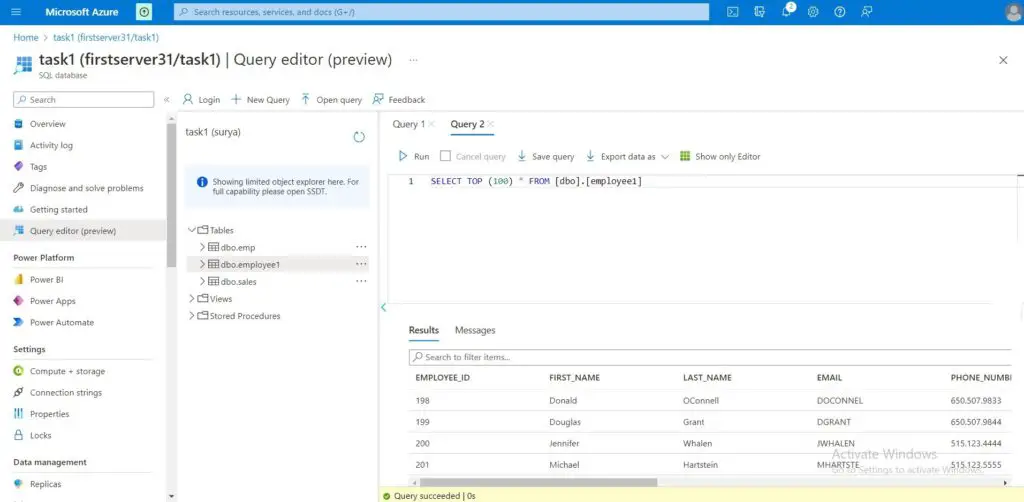
Step 3:- Write CSV File into the Database.
filedf1 = DataFrameWriter(file_df)
filedf1.jdbc(url=url, table="employee1", mode="overwrite", properties=properties)
print("Successfully added Into Database")

#Output :-
In Next Tutorial we will come with the Simple ETL Process by Using the Same Technologies.




{kind=link}